Why sendTransaction Needs Its Own Quota Bucket on Solana (And What Happens When It Doesn't)
This is the failure mode we see most often on Solana trading infra: a bot detects an opportunity perfectly, signs the transaction, hits the RPC provider's sendTransaction, and gets a 429 Too Many Requests. Not because the submit path is overloaded — because the read path spent the budget.
It's a policy problem, not a performance problem. And it's a bug in the pricing model, not in your code.
The anatomy of a spike
Walk through a normal Pump.fun graduation wave on a sniper bot.
Baseline, no wave:
- ~5k
getAccountInfo/ day (token metadata polling). - ~2k
getTokenAccountsByOwner/ day (wallet state). - ~200
sendTransaction/ day (buys + sells). - Total read traffic: ~7k. Submit traffic: 200.
Wave lands. Multiple Pump.fun tokens cross the 85 SOL bonding threshold in the same hour. Your scanner fires harder:
- ~35k
getAccountInfo/ day (confirming new Raydium pools). - ~15k
getTokenAccountsByOwner/ day (wallet state x many tokens). - ~10k
getProgramAccountswith filters (enumerating fresh pools). - ~1k
sendTransaction/ day (chasing the wave). - Total read traffic: ~60k. Submit traffic: 1k.
Read traffic went up ~8×. Submit went up ~5×. Both are legitimate, both are expected during a wave, and both matter. But on a shared credit pool, the read spike eats the submit budget first because credits drain serially — the request that arrives first is the request that gets paid for, regardless of whether it's a read or a write.
Why providers share the pool by default
From the provider's perspective, a single pool is the simplest billing model. One counter per customer, one plan limit, one place to clamp. No interaction effects. It's easy to ship and easy to reason about if you're the provider.
From the customer's perspective it's broken, because sendTransaction isn't a read. It's the thing the entire read path exists to serve. Letting reads starve writes is the exact inverse of what the customer's workload needs.
What "your own bucket" actually means on Subglow
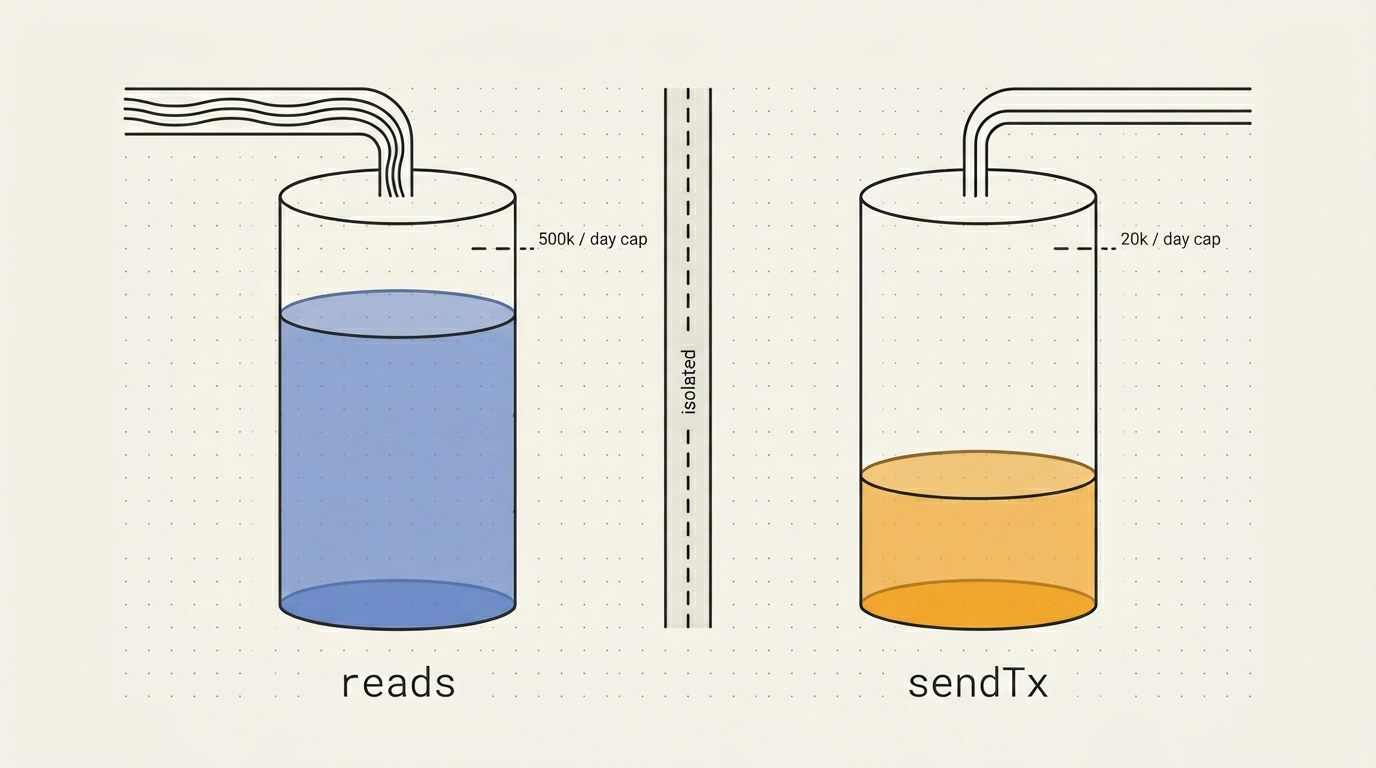
Subglow runs two independent counters per API key, per day:
- Total RPC requests — every method except
sendTransactionandsendRawTransaction. - sendTransaction —
sendTransactionandsendRawTransactiononly.
They decrement independently. Pro tier is 500k RPC/day and 20k sendTx/day. Spiking your reads to 500k has zero effect on the 20k submit budget. You hit a read ceiling or you hit a write ceiling — you never burn one to run out of the other.
The gateway enforces this at the edge. When a request arrives we parse the JSON body, see method: "sendTransaction", increment the sendTx counter in Redis, and check that counter against sendTxDailyLimit. Reads use a separate counter checked against rpcDailyLimit. Same key, same auth, different buckets.
Here's a sketch of the decision in pseudocode:
let kind = if methods::is_send_tx(method) {
QuotaKind::SendTx
} else {
QuotaKind::Rpc
};
match quota.check_and_increment(api_key, kind).await {
Ok(_) => forward_to_upstream(body).await,
Err(QuotaError::Exceeded(kind)) => rpc_error(-32005, format!("{kind}-quota-exceeded")),
}What this buys you
1. Scanner spikes don't kill your submit path
This is the main one. Your bot can read as aggressively as it wants up to the read cap. The submit path is untouched. You will never see a 429 on sendTransaction because you ran a getProgramAccounts too many.
2. Separate buckets let you size each correctly
Most trading bots read 50–200× more than they write. A single shared bucket sized for the read path gives you way more write capacity than you need (wasteful) or sized for the write path gives you way too little read (broken).
Independent buckets mean Subglow can set Pro to 500k reads / 20k writes — which is a 25:1 ratio — and that matches what bots actually do. Users who need wider ratios (write-heavy apps like market makers or liquidators) get a warning in the dashboard and a path to Dedicated where both are unlimited.
3. Debuggable failure modes
When a customer hits a cap, we know exactly which cap. The gateway error is rpc-quota-exceeded or send-tx-quota-exceeded — no ambiguity. The dashboard shows three distinct bars (gRPC, RPC, sendTx) with their own daily totals. You don't have to guess which subsystem exhausted the shared pool.
What this does NOT fix
Two things people sometimes expect and we want to be honest about:
- Confirmation time. Separating the bucket doesn't make
sendTransactionconfirm faster. Subglow forwards submits to the upstream backend, which forwards to the leader. Your submit latency is the same physics as every other RPC provider. What changes is whether your submit goes out at all. - Slot-level priority. We do not prioritize one customer's submit over another's. If you need guaranteed submission capacity regardless of network congestion, that's what Dedicated is for — separate leader lanes, colocated, unlimited submits.
How to verify it's working
On any Subglow plan, hit the dashboard at /dashboard/usage. You'll see three counters:
- gRPC messages delivered today.
- JSON-RPC requests today.
sendTransactiontoday.
The third one decrements only when you submit. Run your bot in read-heavy mode for an hour and the third counter won't move. That's the invariant we built the system around.
Related reading
- The Subglow JSON-RPC product page.
- Flat pricing vs credit metering — why the shared-pool problem is worse under credit metering.
- Method allowlist and archival gating — the other policy layer on the gateway.
- RPC connection docs — client setup examples.
Ready to try it?
Get your API key and start receiving filtered data in under 5 minutes. Free tier available.
Get started →